결측값
import pandas as pd
import numpy as np
# 결측값
# 필요 데이터셋 생성
b=np.arange(12).reshape(4,3)
df=pd.DataFrame(b,
columns=['X1','X2','X3'])
df

# 결측값 만들기
df.loc[1,['X1','X3']]=np.nan
df.loc[2,'X2']=np.nan
df.loc[3,'X2']=np.nan
df

df_0=df.fillna(0) # fillna()로 결측값 채우기
df_0

df_missing=df.fillna('missing') # 문자로도 채울수 있음
df_missing

df_f=df.fillna(method='ffill') # .fillna(method='ffill') 위에 열의 값으로 채워줌
df_f

df_b=df.fillna(method='bfill') # fillna(method='bfill') 밑에 열의 값으로 채워줌
df_b

df_mean=df.fillna(df.mean()) # 각 열의 평균으로 대체하기
df_mean

데이터프레임
x=np.array([1,2,3,4,5])
sample_df=pd.DataFrame({
'col1':x,
'col2':x+2,
'col3':['a','b','c','d','e']})
print(sample_df)
print(sample_df['col2']) # col2만 조회
print(sample_df[['col2','col3']]) #col2, col3 조회
print(sample_df.drop('col2',axis=1)) # col2만 제외
print(sample_df.query('index==0')) # index가 0인 열만 조회

데이터셋 합치기
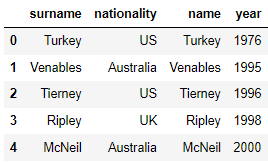
authors=pd.DataFrame({'surname':['Turkey','Venables','Tierney','Ripley','McNeil'],
'nationality':['US','Australia','US','UK','Australia']})
authors

books=pd.DataFrame({'name':['Turkey','Venables','Tierney','Ripley','McNeil'],
'year':[1976,1995,1996,1998,2000]})
books

mer=pd.merge(authors,books,left_on=['surname'], right_on=['name']) # SQL에서의 JOIN과 유사한 방식
mer
mer.drop(['name'],axis=1,inplace=True) # 여기서는 name을 drop
mer

3장 그래프
import seaborn as sns
from matplotlib import pyplot as plt
pi=3.14
x=np.arange(start=0,stop=20,step=0.1)*pi/10
y=np.sin(x)
plt.plot(x,y,color='blue')
plt.title('sine plot')
plt.xlabel('x')
plt.ylabel('sin x')

x=np.random.normal(size=100)
#Basic box plot
plt.boxplot(x)
plt.show()
