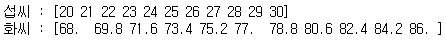import numpy as np
import pandas as pd
import scipy as sp
import math as m
# 2장 연습문제 1
#연습문제 a
print('a :', 1+2*(3+4))
#연습문제 b
print('b :',1+1/2+1/3+1/4+1/5+1/6)
#연습문제 c
print('c :',m.sqrt((4+3)*(2+5)))
#연습문제 d
print('d :', ( (1+2)/(4+5) )**3 )
#연습문제 e
print('e :',122+12*23)
#연습문제 f
print('f :',math.factorial(10))
#연습문제 g
print('g :',math.sqrt( (6**2+4) ))
#연습문제 h
print('h :',m.sin(np.pi/3) + m.cos(np.pi/6))
#연습문제 i
print('i :',m.log10(24)+m.log(10))
#연습문제 j
print('j :',m.sin(np.pi/4))
#연습문제 k
print('k :',m.cos(np.pi/3))
#연습문제 l
print('l :',(1+2+3)/(4+5+6))
#연습문제 m
# 교수님 풀이
sum=0
for i in range(5,12):
sum=sum+i**2
print('m :',sum)
#연습문제 n
x=15
y=3
print('n :',m.sqrt( (3*x**2+2*y**3)/((x+y)*(x-y)) ) )
# 2장 연습문제 2
# (a)
x=np.array([2,3,5,7,9,10])
print('a :',x)
# (b)
x2=x**2
print('b :',x2)
# (c)
print('c :',np.sum(x2))
# (d)
print('d :',x-2)
# (e)
print('e :',np.min(x),np.max(x))
# (f)
x_up=x[x>5]
print('f :',x_up)
# (h)
print('h :',np.matmul(x.T,x))
# (i)
print('i :',np.matmul(x,x.T))
# (j) # 열결합
xc = np.column_stack((x, x2)) #np.hstack : 한개의 열벡터로 만들기, np.column_stack : 두개의 열벡터로 만들기
print('j :',xc)
# (k) # 행결합
xr = np.vstack((x, x2)) # np.row_stack과 동일
print('k :',xr)
# 2장 연습문제 3
# 행렬과 벡터 정의
A = np.array([[1, -1, 4], [-1, 1, 3], [4, 3, 2]])
B = np.array([[3, -2, 4], [-2, 1, 0], [4, 0, 5]])
x = np.array([1, -2, 4]).reshape(3, 1) # reshape하기 이전의 x,y는 각각 열벡터임!!
y = np.array([3, 2, 1]).reshape(3, 1)
# (a)
print(A + B)
# (b)
print(A.T) # .T : 전치행렬 구하기
# (c)
print(np.dot(np.dot(x.T, A), y)) # np.dot : 내적 구하기
# (d)
print(np.dot(x.T, x))
# (e)
print(np.dot(np.dot(x.T, A), x))
# (f)
print(np.dot(x.T, y))
# (g)
print(np.dot(A.T, A))
# (h)
print(np.dot(A,B))
# (i)
print(np.dot(y.T,B))
# (j)
print(np.dot(x,x.T))
# (k)
print(x+y)
# (l)
print(x-y)
# (m)
print((x-y).T)
# (n)
print(np.dot(x,y.T))
# (o)
print(A-B)
# (p)
print(A.T+B.T)
# (q)
print((A+B).T)
# (r)
print(3*x)
# (s)
print(np.dot(x.T,y)**2)
# (t)
print(np.dot(B,A))
# (u)
np.linalg.inv(A) # np.linalg.inv() : 역행렬 구하는 함수
# 2장 연습문제 4
# (a)
print(['a']*8)
# (b)
print(np.repeat(np.arange(1, 6), 3))
# (c)
x=np.arange(1,101)
x[x%2==1]
# (d)
np.array([1,5,19,30])
# (e)
np.arange(-10,11)
# 2장 연습문제 5
x=np.arange(1,11) # 1~10까지 정수들을 갖는 벡터
# (a)
len(x)
# (b)
np.sum(x)
# (c)
np.mean(x)
# (d)
print(np.var(x,ddof=1)) # 불편 분산
print(np.std(x, ddof=1)) # 불편 표준편차
#ddof=0은 MLE기법으로 구한 것!
# (e)
odd=x[np.where(x%2==1)] # np.where을 사용하여 조건식 부여
odd
# (f)
sum=0
for i in range(1,11) :
sum = sum + x[i-1]/i
print(sum)
# 2장 연습문제 6
brother=pd.DataFrame({'id':np.arange(1,7), 'elder':[86,71,77,68,91,72],'younger':[88,77,76,64,96,72] })
print(brother.T)
# (a)
brother.T.to_csv('C:/Users/user/Desktop/건대 수업/통전처/brother.txt', header=False, index=True)
# (b)
brother.T.to_csv('C:/Users/user/Desktop/건대 수업/통전처/brother_e.csv', header=False, index=True)
# (c)
print('형의 평균 :',brother['elder'].mean(),'형의 표준편차 :', brother['elder'].std())
print('동생의 평균 :',brother['younger'].mean(),'동생의 표준편차 :', brother['younger'].std())
# (d)
elder_mean_std = {'mean': brother['elder'].mean(), 'std': brother['elder'].std()}
younger_mean_std = {'mean': brother['younger'].mean(), 'std': brother['younger'].std()}
print(elder_mean_std,younger_mean_std)
df = pd.DataFrame([elder_mean_std, younger_mean_std], index=['elder', 'younger'])
df.to_csv('result.csv')
# 2장 연습문제 7
# (a)
x=np.array([-4.123,-3.556,1.634,2.213,3.875])
print(x)
# (b)
y=np.trunc(x*100)/100
print(y)
# (c)
print(x-y)
# (d)
print(np.round(x,1))
# (e)
print(np.ceil(x))
# (f)
print(np.floor(x))
# 2장 연습문제 8번
# 데이터셋을 딕셔너리로 정의하면서 행 이름을 설정
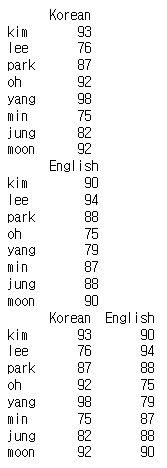
data1 = {'Korean': [93, 76, 87, 92, 98, 75, 82, 92]}
data2 = {'English':[90,94,88,75,79,87,88,90]}
index_names = ['kim', 'lee', 'park', 'oh', 'yang','min','jung','moon']
# 딕셔너리를 데이터프레임으로 변환하면서 행 이름을 설정
Korean = pd.DataFrame(data1, index=index_names)
English = pd.DataFrame(data2, index=index_names)
# 데이터프레임 출력
print(Korean)
print(English)
# (a)
result = pd.concat([Korean, English], axis=1) # axis=1은 열방향으로 결합하게 만들어줌
print(result)
# (b)
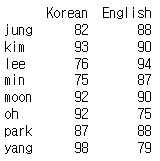
# 인덱스를 알파벳 순으로 정렬
result_sorted = result.sort_index() # sort_index()를 통해 인덱스를 알파벳순으로 정렬
print(result_sorted)
# 2장 연습문제 9번
# 데이터셋 만들기
class1=pd.DataFrame({'1반':['kim','lee','park','oh','ang','min','jung','moon'],
'국어':[93,84,87,95,98,77,82,92]})
class2=pd.DataFrame({'2반':['kang','yun','park','cho','yang','min','jung','choi'],
'국어':[90,95,88,75,79,87,90,90]})
# 데이터 확인
print(class1)
print(class2)
#(b)
Name= pd.concat([class1['1반'],class2['2반']])
Korean=pd.concat([class1['국어'],class2['국어']])
df3 = pd.DataFrame({'이름': Name, '국어': Korean})
df3
print('1,2반 전체 평균 : ',df3['국어'].mean(),'\n1,2반 전체 표준편차 : ',df3['국어'].std())
# (c)
sort_df3=df3.sort_values(by='Name') # 'Name'열의 값들을 sort
sort_df3
# 2장 연습문제10
x=np.arange(20,31)
y=9/5*x+32
print('섭씨 :',x)
print('화씨 :',y)
# 2장 연습문제 11
# 11번
def area(radius) :
return(np.pi*radius*radius) # 사용자 지정 함수로 원 넓이를 구하는 함수 만들기
r=np.array([1,2,4,7,10]) # 구하고 싶은 반지름 array 만들기
for i in range(len(r)) :
print('radius:', r[i], '-> area : ',area(r[i])) # for문 이용하여, 각 반지름별 원의 넓이 구하기!
# 2장 연습문제 12
r=np.array([1.5,3])
v=4/3*np.pi*r**2
print(v)
# 2장 연습문제 13
# (a)
a=8
print(type(a)) # int
# (b)
a=8.0
print(type(a)) # float
# (c)
a='8'
print(type(a)) # str
# (d)
a=(8)
print(type(a)) # int
# (e)
a=[1,2,3]
print(type(a)) # list
# (f)
a=(1,2,3)
print(type(a)) # tuple
# (g)
a=False
print(type(a)) # bool