23.10.30
<> : 엑셀에서의 not equal 의미
countifs에서 0이상 나타내고 싶으면 =COUNTIFS($F:$F,$N$11,$G:$G,"<" & O11) 이렇게 표현
sumif : 특정 조건을 만족하는 데이터의 합계 계산
FIND 함수 : 긴 텍스트에서 특정 단어나 문장이 시작하는 위치를 숫자로 출력
띄어쓰기까지 포함하여 문자를 세며 대소문자를 구분 → 대소문자를 구분하지 않아야 할 때는 SEARCH 함수를 사용
LEFT, RIGHT, MID함수 :
LEN 함수 : 전체 텍스트의 길이를 알 수 있음
year함수 : 연도 추출
=YEAR(B5)&"년”
엑셀은 1900년 1월 1일을 1일로 계산함
날짜가 잘못되어있으면 99% 서식이 잘못 되어진 것
텍스트 나누기 : 데이터 → 텍스트 나누기 → 구분 기호로 분리도미 → 기타 체크 → “-”입력 → 마침
필터 단축키 : ctrl shift L
f4 : 마지막에 했던 명령을 실행
데이터유효성 검사 : 특정 셀이나 범위에, 상황에 따라 내가 유효하다고 인정하는 데이터만 입력되게 하는 기능
셀이나 범위 선택 → 데이터 탭 → 데이터 유효성 검사 → 목록 → 데이터 직접 입력 or 목록 범위 설정
클릭만 하면 목록 내에 있는 조건으로 하는 그래프를 그릴 수도 있다
통계학 : 모집단으로부터 자료를 수집, 정리 , 요약을 하고 표본 정보로부터 자료를 추출했던 대상 전체인 모집단에 대해 추론 (요약 : 일부분으로 전체를 파악하려는 것)
가설 검정: 통계적 추론의 하나로서, 모집단 실체의 값이 얼마가 된다는 주장과 관련해, 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정
p-value : 귀무 가설이 맞다는 전제 하에, 표본에서 실제로 관측된 통계치와 ‘같거나 더 극단적인’ 통계치가 관측될 확률
유의점 : p-value는 관계나 집단들 사이에 차이가 생겨나는 것이 우연한 것인지, 변수에 의한 것인지 여부를 밝히는 것. 하지만 이것이 효과나 변화의 정도, 관계의 강도나 크기 등을 설명하는 것은 아님!!
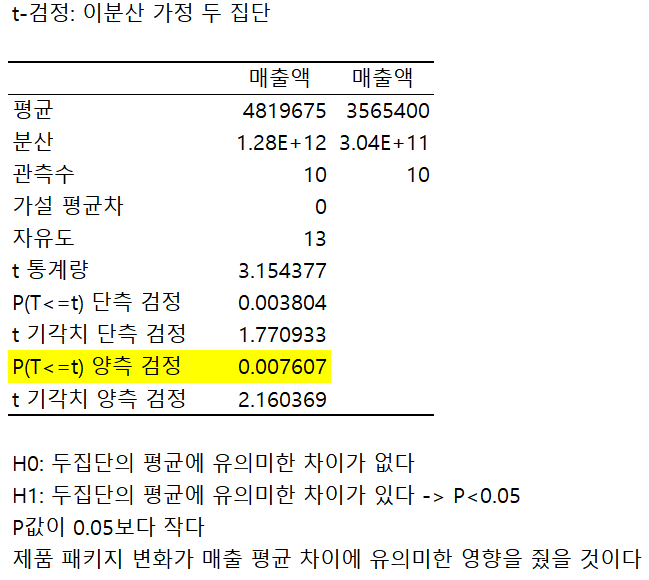
t-test : 두 집단(또는 한 집단의 전/후)의 평균에 통계적으로 유의미한 차이가 있는지를 결정.
t-test 시행단계 : 변수(집단)선택 → F-검정 → t-test → 결과 해석
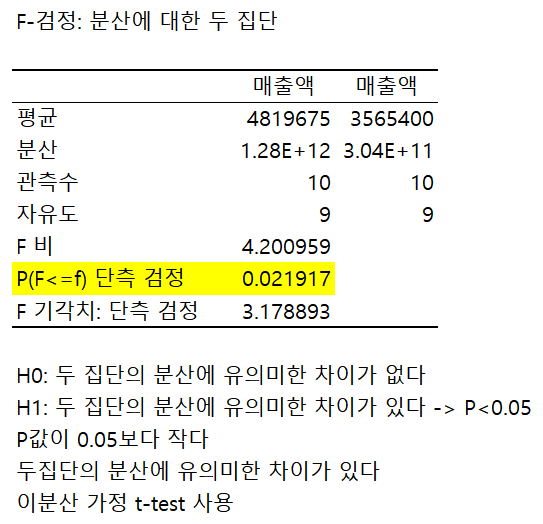
F-검정 : 두 집단의 분산에 통계적으로 유의미한 차이가 있는지를 검정
p-value가 0.05보다 크면 두 집단의 분산에 유의미한 차이가 없고, 0.05보다 작으면 두 집단의 분산에 유의미한 차이가 있다
예시)
23.11.01
회귀분석 : 두 개 이상의 연속형 변수인 종속 변수와 독립변수 간의 관계를 파악하는 분석
목적 : 두 변수간의 관계를 파악해 우리가 알고 싶은 값을 예측하는 것
오차=실제값 - 예측값
단순선형회귀 분석의 평가와 해석 :
결정계수 / 유의한 F값 / y절편 및 x1의 계수 확인
회귀분석의 귀무가설 : 모형 유의미하지 않다 / 대립가설 : 모형 유의미하다
F값의 p-value가 0.05보다 크면 모형이 유의하지 않음
다중선형 회귀분석의 평가와 해석 :
조정된 결정계수 / F값 / Y절편 미 각 독립 변수의 p-value와 계수 확인
조정된 결정계수 쓰는 이유 : 결정계수에서는 영향력이 떨어지는 변수들도 다 포함하기 때문에 더 정확하게 해석 위해선 조정된 결정계수 사용
다중선형 회귀는 모든 변수들을 다 쓰는 것이 아니라 유효한 변수들만 채택해서 사용함!
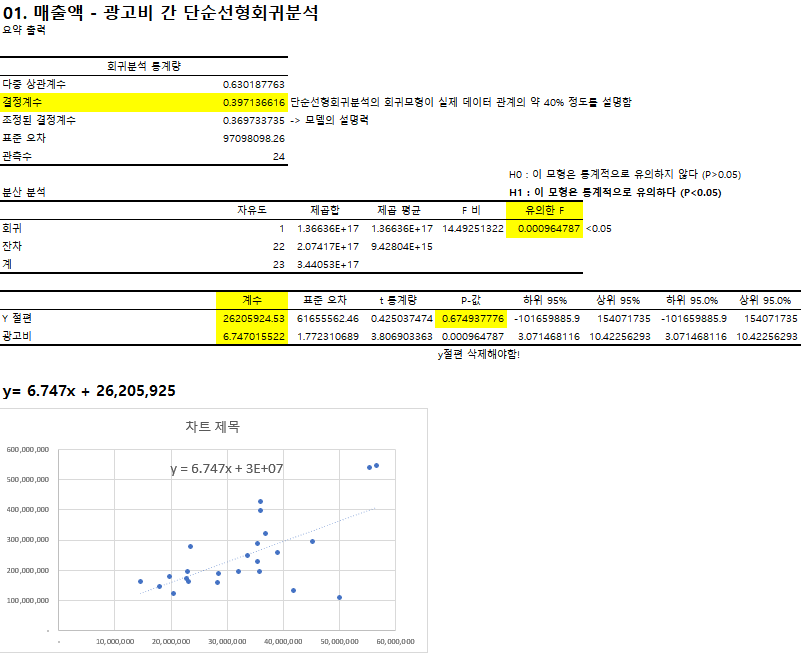
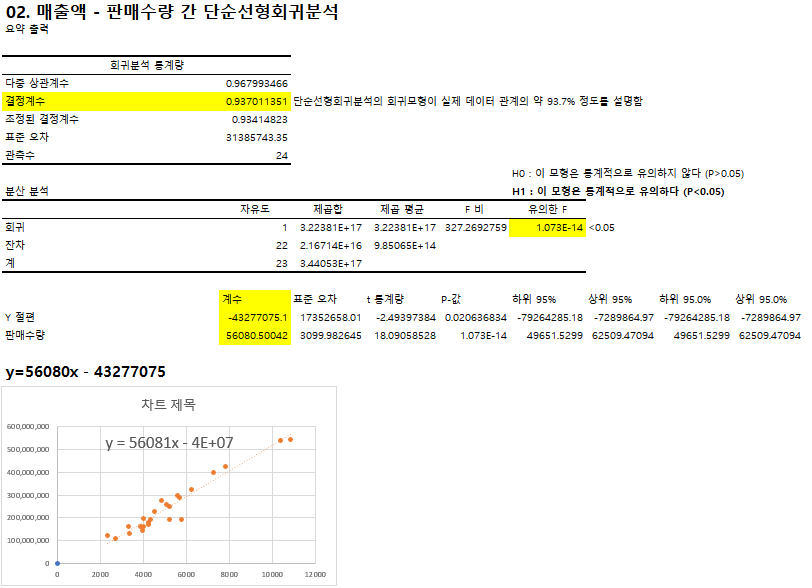
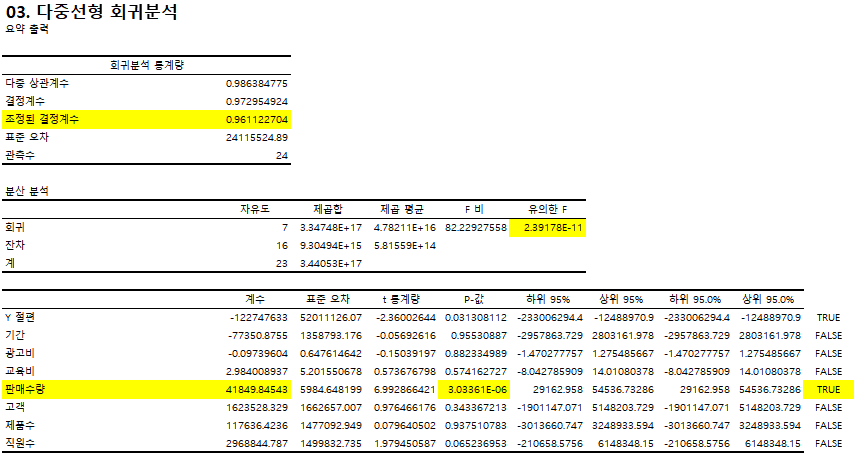
∴매출액을 예측하기 위해서는 판매수량이 광고비 보다 더 좋은 변수이다
강사님은 아래 플로우로 실시함
0. 상관분석 - 상관 관계가 강한 변수 도출
1. 다중선형회귀분석 - 모든 변수로
2. 다중선형회귀분석 - 유의미한 변수들로
3. 단순선형회귀분석 - 유의미한 변수들 각각
시계열 데이터 분석 : 시간의 흐름에 따라 발생된 데이터를 분석하는 기법
정상성 : 추세나 계절성을 가지고 있지 않으며, 관측된 시간에 무관한 성
대부분의 시계열 데이터는 비정상 시계열 데이터인데, 비정상 시계열 데이터인 상태로는 분석이 어렵기 때문에 차분이나 다른 방법을 활용해 비정상 시계열 데이터를 정상 시계열 데이터로 변환해 분석하기도 함
지수평활법(exponential smoothing) : 현재 시점에 가까운 시계열 자료에 큰 가중치를 주고, 과거 시계열 데이터일수록 작은 가중치를 주어 미래 시계열 데이터를 예측하는 기법
머신러닝 : 컴퓨터가 어떤 작업(T,task)을 하는데 있어서 경험(E,experience)으로부터 학습하여 성능(P,performance)을 향상시키는 학문
지도학습 : 정답이 있는 데이터를 활용해 데이터를 학습하고, 학습한 모델이 얼마나 정답을 정확하게 맞추는지 평가하는 학습. 분류, 회귀 문제들을 해결할 수 있음.
비지도학습 : 정답이 없는 데이터를 활용해 데이터를 학습. 데이터가 어떻게 구성되어 있는지, 혹은 어떻게 분류될 수 있는지에 대한 문제 해결.
강화학습 : 에이전트(학습 시스템)가 취한 행동에 대한 보상 또는 벌점을 주어 가장 큰 보상을 받는 방향으로 유도하는 방법. 가장 큰 보상을 얻기 위해 에이전트가 해야 할 행동을 선택하는 방법을 저의하게 되는데 이를 ‘정책’이라고 함.
데이터 시각화는 도구가 아니라 전략이다.
차트를 그릴 때 고민해야 하는 3가지 Question
- 어떤 숫자로 차트를 그릴 것인가?
- 어떤 차트가 숫자를 가장 잘 설명하는가?
- 차트를 어떻게 디자인하는게 가장 효과적인가?
차트=숫자의 다른 표현
차트를 효과적으로 디자인 할 수 있는 4단계 원칙 :
1. 차트의 모든 데이터를 단색으로 변경(회색 추천)
2. 차트에서 가장 중요한(강조해야 하는) 데이터 선정
3. 차트의 메인 컬러(1개) 선택
4. 2의 중요 데이터에만 3의 메인 컬러 적용
+ 데이터 레이블(숫자) 추가
+ 차트의 윤곽선 제거
엑셀에서 테두리 없애기 : 보기→ 눈금 체크해제
콤보차트 : 데이터 범위 선택 → 막대형 차트 삽입 → 그래프의 막대 선택 → 마우스 오른쪽 클릭 →계열차트변경 → 필요한 경우[보조 축] 선택
거품형 차트 : x, y, 거품크기 순으로 데이터 지정 → [삽입]에 거품형 차트 → 축 클릭해서 우클릭 → 축서식에서 최대 최소 변경 → 거품 우클릭해서 채우기에 [요소마다 다른 색 사용] 클릭
폭포형 차트 : 데이터 선택 → [삽입]에 폭포형 차트 → 현재에 우클릭 해서 합계로 지정
분석은 거창해서는 안된다? → 구체적인것!
'[패캠] 데이터분석 부트캠프 > 수업 정리' 카테고리의 다른 글
| 패스트캠퍼스 BDA 부트캠프 | 7주차 과정(MySQL) (0) | 2024.09.04 |
|---|---|
| 패스트캠퍼스 BDA 부트캠프 | 6주차 과정(MySQL) (1) | 2024.09.04 |
| 패스트캠퍼스 BDA 부트캠프 | 4주차 과정(파이썬) (0) | 2024.09.04 |
| 패스트캠퍼스 BDA 부트캠프 | 3주차 과정(파이썬) (0) | 2024.09.04 |
| 패스트캠퍼스 BDA 부트캠프 | 1주차 과정(엑셀) (0) | 2024.09.03 |